Athena Abfragen mit Python automatisieren
Athena Abfragen mit Python automatisieren
Einleitung
In den letzten Wochen hatte ich die Gelegenheit mit einigermaßen intensiv mit Amazon Athena zu beschäftigen. Für alle, die damit bisher noch keine Berührungspunkte hatten, mit Athena kann man im Kern SQL-Abfragen auf Daten, die in S3 liegen durchführen (unter der Haube ist Athena ein managed Hive/Presto Cluster). Das Abrechnungsmodell ist auch einigermaßen attraktiv - man bezahlt nur für die Menge an verarbeiteten Daten und hier sind die kosten bei ca. $5/TB auch sehr überschaubar, wenn man bedenkt, wie aufwändig es ist einen EMR Cluster für seltene oder einmalige Abfragen aufzusetzen.
In diesem Blog-Post zeige ich euch, wie man Athena mit Python automatisieren kann.
Athena verwenden
Interaktiv
Wenn man Athena interaktiv, also in der AWS Konsole, benutzt ist das denkbar einfach - in der GUI findet man die angelegten Schemata und Tabellen auf der linken Seite und rechts oben den SQL Editor. Nachdem man das SQL Statement geschrieben hat, benutzt man den großen blauen Run query Button, lehnt sich zurück, bewundert den Ladebalken und hat nach einigen Sekunden unten rechts das Ergebnis, was man auch als CSV herunterladen kann.
Innerhalb des Codes
Athena aus Scripten o.ä. zu nutzen ist ein bisschen nerviger - zumindest, wenn man Lambda verwendet oder versucht die Architektur Serverless zu gestalten.
SQL-Abfragen über das Python SDK abzuschicken ist relativ einfach - wenn man das Standard-boto3 verwendet, sieht das ungefähr so aus:
import boto3
query = "Your query"
database = "database_name"
athena_result_bucket = "s3://my-bucket/"
response = client.start_query_execution(
QueryString=query,
QueryExecutionContext={
'Database': database
},
ResultConfiguration={
'OutputLocation': athena_result_bucket,
}
)
query_execution_id = response["QueryExecutionId"]
Queries starten ist ja gut und schön, meistens interessiert uns aber auch das Ergebnis - oder zumindest, ob die Abfrage erfolgreich ausgeführt wurde.
Hier haben wir das Problem, dass Athena Queries sich in Bezug auf die Laufzeit eher im Bereich von Sekunden und Minuten als Millisekunden bewegen - die harte Obergrenze liegt hier bei 30 Minuten. Wenn wir mit Lambda arbeiten ist das ein Problem, weil die maximale Laufzeit für Lambda-Funktionen derzeit 15 Minuten beträgt - Langläufer-Lambdas sind aber eh nicht so schön. (Falls Ihr von vornherein wisst, dass die Queries nicht lange brauchen, könnt ihr direkt zum Abschnitt “Schnelle Queries” springen.)
Step Functions to the rescue! Ja ich weiß, einen weiteren Service für dieses Problem zu nutzen, ist nicht ideal, aber Athena hat aktuell zwei entscheidende Limitierungen:
- Es gibt keinen Lambda-Trigger, wenn eine Query beendet wurde
- Es gibt auch keine Integration in SNS, SQS oder ähnliches, wenn Queries beendet werden
Kurz: Athena fehlen Integrationen für beendete Queries (falls ich etwas übersehen haben sollte, meldet euch gerne).
Falls euch Step Functions bisher noch nicht über den Weg gelaufen sind: Das ist ein Service, in dem ich komplexe Workflows definieren kann, die zum Beispiel mehrere Lambda-Funktionen enthalten. Diese Workflows werden als State Machine / Zustandsautomat definiert.
Meine Step Functions für Langläufer-Queries sehen meistens so aus:
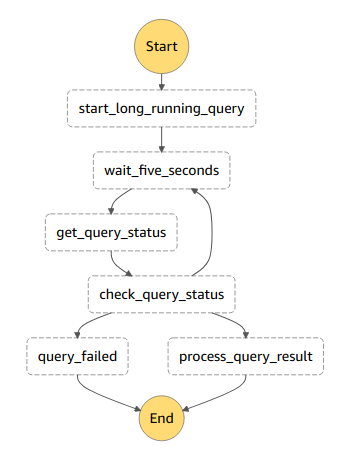
Eine Lambda-Funktion startet die Query und gibt die ID der Ausführung an die nächsten Schritte weiter. Jetzt beginnt eine Form von Schleife - wir warten zunächst fünf Sekunden in einem Wait-Step, dann wird eine weitere Lamda Funktion getriggert, die den aktuellen Status der Ausführung abruft. Ein Entscheidungsschrit (Choice-Step) definiert dann, unter welchen Bedingungen welcher weg genommen wird. Falls die Query noch läuft oder sich noch in der Warteschlange befindet, geht es zurück zum Warten-Schritt. Falls es einen Fehler gibt, wechseln wir zu einem Fehlerzustand und wenn die Query erfolgreich durchgelaufen ist, verarbeiten wir das Ergebnis in einer weiteren Lambda Funktion.
Ein Beispielprojekt mit dem Code und der State-Machine könnt ihr auf Github finden. Um mir das Leben leichter zu machen, habe ich die athena_helper.py mini-library geschrieben, die einige der nervigen Teile der AWS API abstrahiert.
Als nächstes Zeige ich auch den Code für Langläufer-Queries und anschließend schauen wir uns den einfachen Fall mit schnellen Queries an.
Athena automatisieren
Langläufer-Queries
Wie bereits erwähnt, sind drei Lambda-Funktionen involviert - wir beginnen mit der Funktion, welche die Query ausführt:
def start_long_running_query(event, context):
# This is the default table
query = "select * from elb_logs limit 1"
database_name = "sampledb"
# Build the name of the default Athena bucket
account_id = BOTO_SESSION.client('sts').get_caller_identity().get('Account')
region = BOTO_SESSION.region_name
result_bucket = "s3://aws-athena-query-results-{}-{}/".format(account_id, region)
my_query = AthenaQuery(query, database_name, result_bucket)
query_execution_id = my_query.execute()
# This will be processed by our waiting-step
event = {
"MyQueryExecutionId": query_execution_id,
"WaitTask": {
"QueryExecutionId": query_execution_id,
"ResultPrefix": "Sample"
}
}
return event
Die Funktion bereitet zunächst die Parameter für die Query vor:
query- das SQL-Statement selbstdatabase_name- der Name des Schemas, in dem die Query ausgeführt wirdresult_bucket- der Name des S3-Buckets, in dem die Ergebnisse gespeichert werden sollen - hier baue ich den Namen des Standard-Athena-Buckets dynamisch zusammen
Der eigentliche Code für die Ausführung der Query besteht nur aus zwei Zeilen. Wir erzeugen ein AthenaQuery Objekt und führen die execute() funktion darauf aus. Als Ergebnis erhalten wir die Query Execution Id, welche die Ausführung eindeutig identifiziert.
my_query = AthenaQuery(query, database_name, result_bucket)
query_execution_id = my_query.execute()
Anschließend bauen wir das Rückgabe-Objekt für Lambda zusammen - das wird der Input für den Status-Abruf. Prinzipiell wäre es ausreichend, wenn wir hier die Query Execution Id weitergeben, aber ich mag Statistiken und dafür werden einige Vorbereitungen getroffen.
Die nächste Lambda Funktion ruft den Status der Ausführung ab und ist erheblich simpler. Aus der QueryExecutionId wird ein AthenaQuery Objekt gebaut und anschließend der Status, sowie einige Statistiken über die Query abgerufen und im Ergebnis-Objekt gespeichert.
def get_long_running_query_status(event, context):
query_execution_id = event["WaitTask"]["QueryExecutionId"]
aq = AthenaQuery.from_execution_id(query_execution_id)
status_information = aq.get_status_information()
event["WaitTask"]["QueryState"] = status_information["QueryState"]
status_key = "{}StatusInformation".format(event["WaitTask"]["ResultPrefix"])
event[status_key] = status_information
return event
Der Choice-Step in der Step Function definiert, wie diese Ausgabe verarbeitet wird, hier ist ein Auszug aus der Definition der State Machine - die vollständige Definition findet sich in der serverless.yml im Repository:
check_query_status:
Type: Choice
Choices:
- Or:
- Variable: "$.WaitTask.QueryState"
StringEquals: FAILED
- Variable: "$.WaitTask.QueryState"
StringEquals: CANCELED
Next: query_failed
Dieser Auszug sagt der State Machine, dass in den Fehlerzustand query_failed übergegangen werden soll, falls die Query im Status FAILED oder CANCELED ist.
Wir gelangen nur zum nächsten Schritt der Verarbeitung, falls die Query erfolgreich war. Diese Lambda Funktion baut wieder ein AthenaQuery Objekt und ruft das Ergebnis ab:
def get_long_running_result(event, context):
query_execution_id = event["MyQueryExecutionId"]
# Build the query object from the execution id
aq = AthenaQuery.from_execution_id(query_execution_id)
# Fetch the result
result_data = aq.get_result()
# Do whatever you want with the result
event["GotResult"] = True
return event
Innerhalb der Lambda Funktion könnt ihr dann mit der Ergebnis machen, was ihr möchtet.
Schauen wir uns jetzt den einfacheren Fall an, schnelle Queries:
Schnelle Queries
Dieses Vorgehen würde ich für Queries mit einer Laufzeit von maximal 5 Minuten empfehlen - andernfalls lohnt es sich wahrscheinlich, die State Machine aufzusetzen.
Dieser Code basiert ebenfalls auf der athena_helper.py:
import boto3
from athena_helper import AthenaQuery
BOTO_SESSION = boto3.Session()
def short_running_query(event, context):
# Build the name of the default Athena bucket
account_id = BOTO_SESSION.client('sts').get_caller_identity().get('Account')
region = BOTO_SESSION.region_name
result_bucket = "s3://aws-athena-query-results-{}-{}/".format(account_id, region)
my_query = AthenaQuery(
"select elb_name from elb_logs limit 1",
"sampledb",
result_bucket
)
my_query.execute()
result_data = my_query.get_result()
# Process the result
return result_data
Hier werden die gleichen Funktionen wie oben beschrieben verwendet - abgesehen von dem zusätzlichen Waiting-Step in der Mitte. Die get_result() Funktion wartet im default bis zu 60 Sekunden auf ein Ergebnis, ein längerer Wert kann über query_timeout=XXX im Konstruktor der AthenaQuery übergeben werden.
Zusammenfassung
In diesem Post habe ich euch gezeigt, wie man die athena_helper mini-library verwenden kann, um kurze und lange Athena-Queries mit Python zu automatisieren.
Bei Fragen, Anmerkungen oder Kritik meldet euch gerne per E-Mail oder auf Twitter (@Maurice_Brg)
Photo by Hitesh Choudhary on Unsplash