Lambda Destinations can improve success- and error handling for asynchronous Lambda Functions
I may be a bit late to the party here since this feature was announced in late 2019, but since there is so much going on in the Serverless space, I thought I might not be the only one that didn’t have a chance to play around with it yet. In this post, I’ll explain the destination feature, the intended use cases, and what you can expect when you use it through a simple demo application. I won’t talk about destinations for stream-based invocations here because that would increase the scope of this post too much. Maybe another time. Let me know if you’re interested.
Destinations are useful for Lambda functions that are invoked asynchronously. This means the function is invoked, but the party that triggers it doesn’t wait for the function to finish before continuing. An example of this would be an invocation from S3. When S3 triggers a Lambda function because an object has been uploaded to a bucket, it doesn’t wait for the Lambda function to finish what it’s doing because it doesn’t care about the result.
Under the hood, this uses the Invocation Type Event as specified in the API documentation. The API caller usually only receives an HTTP 202 response indicating that the request was accepted. You can invoke a function like this yourself using the AWS CLI. Here is an example:
$ aws lambda invoke --function-name LambdaDemo --invocation-type Event --no-cli-pager /dev/null
{
"StatusCode": 202
}
Asynchronous invocations are excellent if you don’t immediately need the function call result because they don’t block the main flow of events. Whichever process triggers the function can continue its work almost without any delay. The Lambda service will manage the execution in the background. That includes potential retries in case of errors and things like that. While this is nice, it’s often not the whole story. Usually, we don’t care about the result right now, but at some point, we want to know what happened - or at least if the invocation was successful or failed.
In the past, there were a few ways we could do that. Lambda could send failures that persist even after retries to a dead-letter queue for later evaluation. While that’s good for failures, there wasn’t a good way to respond to successful invocations besides triggering some other service or function from within your function code. Destinations improve this situation significantly.
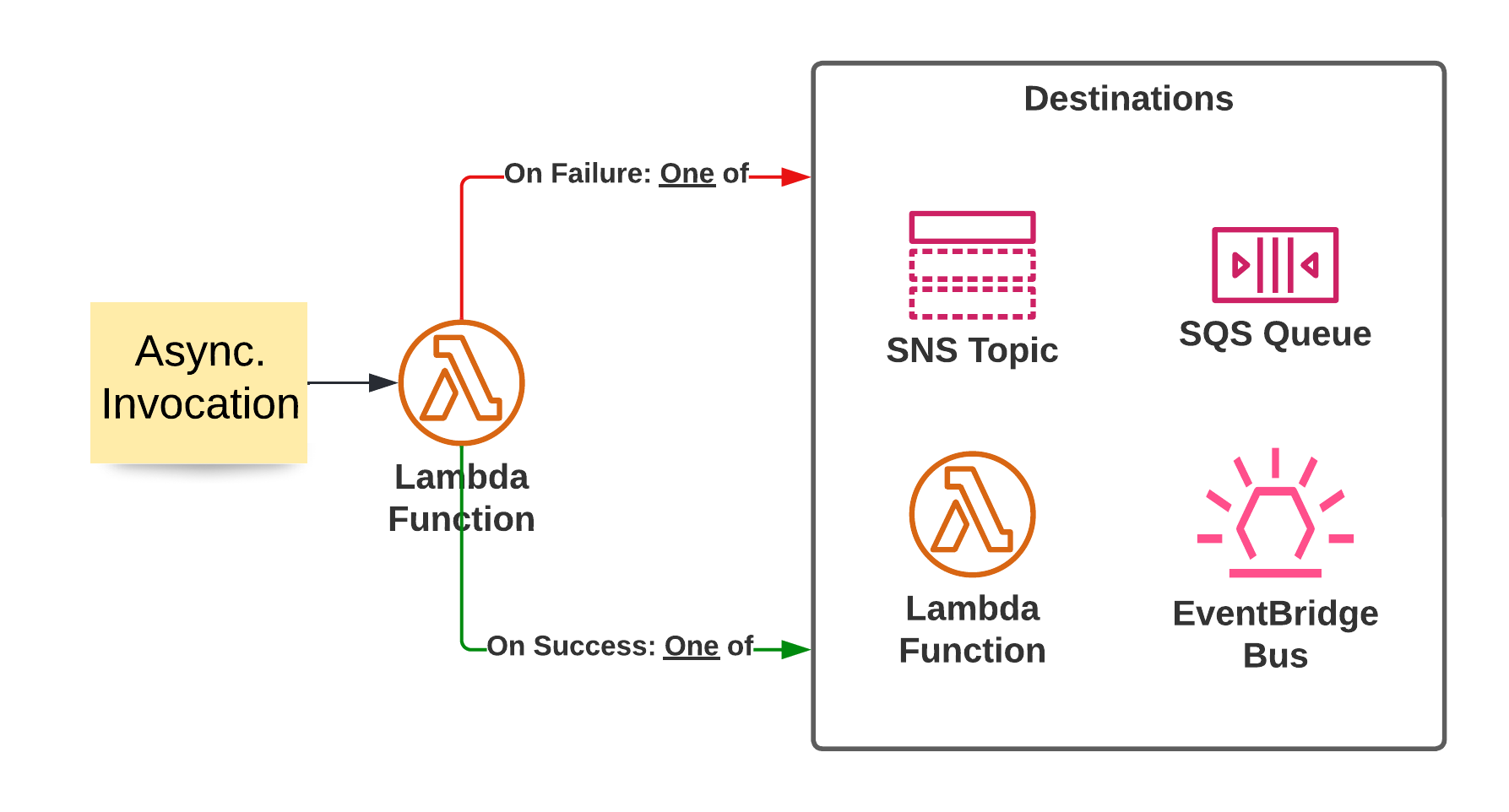
Lambda Destinations allow you to specify what to do if an asynchronous invocation succeeds or fails. You can pass on the information to either Lambda Function, an SNS Topic, an SQS queue, or an EventBridge Event Bus to handle these events. This has the benefit that you may be able to remove parts of your success handling logic from your function code and let the service handle it. Also, it opens the door to different error handling mechanisms that may be more suitable than just catching an error in SQS.
Let’s build a demo app to show what this can do. I have created a CDK app that deploys two Lambda Functions. You can find the code in the companion repository on Github. One function acts as a sender, and the other is the receiver. The receiving function is configured for both the success and failure destination of the sender.
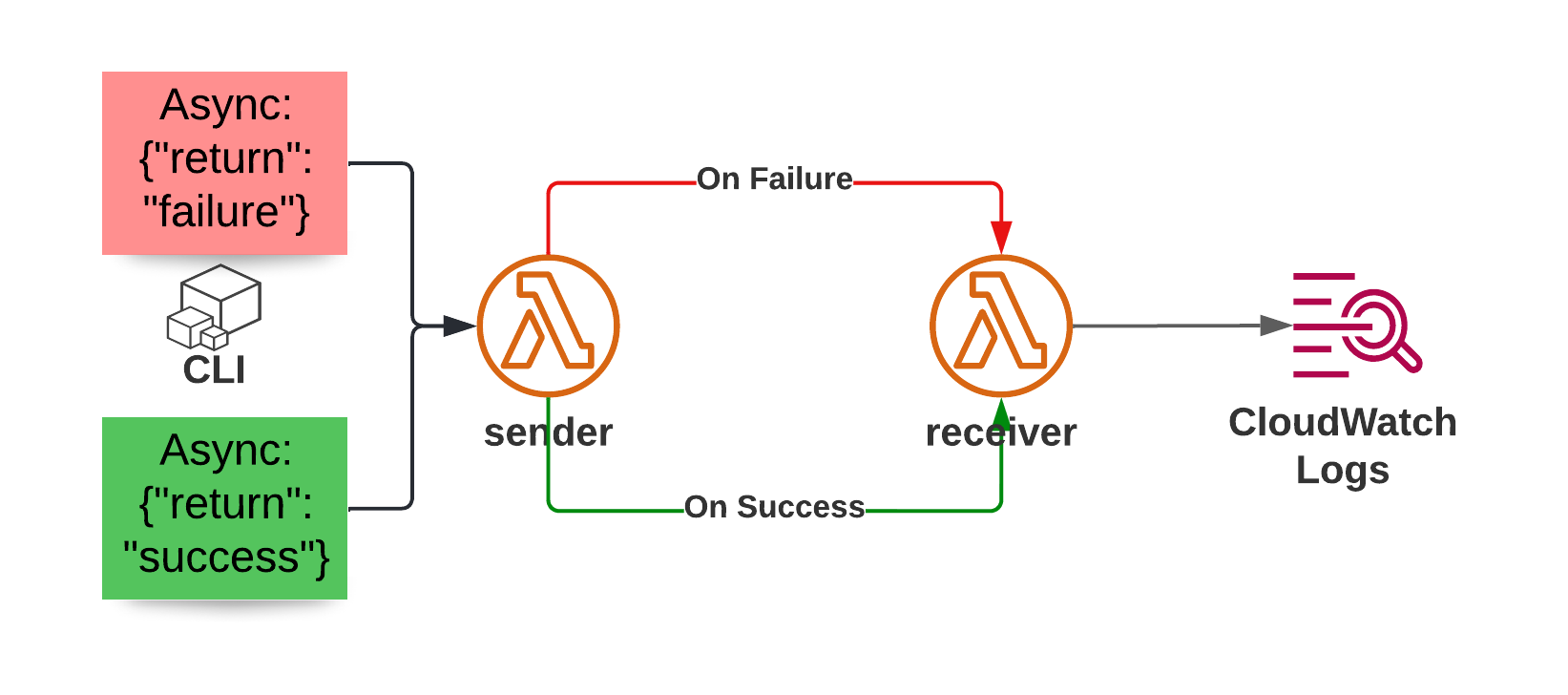 The sender function is fairly basic and will either return success or raise an exception based on the event it receives:
The sender function is fairly basic and will either return success or raise an exception based on the event it receives:
from typing import Any
# We expect events in this form:
# {"return": "failure|success"}
def lambda_handler(event: dict, context: Any) -> dict:
if event.get("return", "failure") == "failure":
# By default we return a failure
raise RuntimeError("I'm supposed to fail here")
else:
return {"this_invocation": "was_successful"}
The receiver is even simpler than that, it only prints the event it receives as input, so we can understand which data is available in these cases.
import json
from typing import Any
def lambda_handler(event: dict, context: Any) -> dict:
print(json.dumps(event))
Deployment of the CDK app yields two outputs that trigger our sender through the AWS CLI (v2) asynchronously. The function name may be different for you.
$ cdk deploy
# [,,,]
Outputs:
CdkLambdaDestinationsStack.invokefailure = aws lambda invoke --function-name CdkLambdaDestinationsStack-sender96A36763-zpInOlEaxILF --invocation-type Event --payload 'eyJyZXR1cm4iOiAiZmFpbHVyZSJ9' --no-cli-pager /dev/null
CdkLambdaDestinationsStack.invokesuccess = aws lambda invoke --function-name CdkLambdaDestinationsStack-sender96A36763-zpInOlEaxILF --invocation-type Event --payload 'eyJyZXR1cm4iOiAic3VjY2VzcyJ9' --no-cli-pager /dev/null
Stack ARN:
# [...]
Next, I run the two commands that the CDK output shows me and inspect the CloudWatch logs of the receiver function. Here you can see the event our receiver gets for a failed invocation:
{
"version": "1.0",
"timestamp": "2022-04-16T11:24:43.658Z",
"requestContext": {
"requestId": "17b37350-871d-4d69-9b4f-a77c2ddd7fc9",
"functionArn": "arn:aws:lambda:eu-central-1:123123123123:function:CdkLambdaDestinationsStack-sender96A36763-zpInOlEaxILF:$LATEST",
"condition": "RetriesExhausted",
"approximateInvokeCount": 3
},
"requestPayload": {
"return": "failure"
},
"responseContext": {
"statusCode": 200,
"executedVersion": "$LATEST",
"functionError": "Unhandled"
},
"responsePayload": {
"errorMessage": "I'm supposed to fail here",
"errorType": "RuntimeError",
"requestId": "17b37350-871d-4d69-9b4f-a77c2ddd7fc9",
"stackTrace": [
" File \"/var/task/sender_handler.py\", line 9, in lambda_handler\n raise RuntimeError(\"I'm supposed to fail here\")\n"
]
}
}
We can see that the original payload of the lambda function was passed along and a detailed error message, including the stack trace. Furthermore, we get the request-id and more information to help our debugging efforts. For a successful invocation, we receive less information. There is still everything included we could need if we wanted to debug the lambda function, though. In addition to that, we see the input and output of the Lambda function, which we can use for further processing.
{
"version": "1.0",
"timestamp": "2022-04-16T11:28:07.537Z",
"requestContext": {
"requestId": "04e16a9b-93b2-4404-bbca-bc29174796ef",
"functionArn": "arn:aws:lambda:eu-central-1:123123123123:function:CdkLambdaDestinationsStack-sender96A36763-zpInOlEaxILF:$LATEST",
"condition": "Success",
"approximateInvokeCount": 1
},
"requestPayload": {
"return": "success"
},
"responseContext": {
"statusCode": 200,
"executedVersion": "$LATEST"
},
"responsePayload": {
"this_invocation": "was_successful"
}
}
It’s also possible to stop passing the input of the original Lambda function to the destination. In my case, I stuck to the default of passing it along. Depending on the kind of data in your input, it may be prudent not to pass it along if it’s very sensitive.
An interesting edge case concerns FIFO queues and topics. For some reason, FIFO SNS topics are supported as Lambda Destinations, and FIFO SQS queues aren’t. I’m not sure why.
In this article, we explored Lambda destinations for asynchronous invocations. We learned about which problems they solve and how you may be able to use them to respond to successful and failed invocations of a Lambda function.
Hopefully, you learned something useful from this article. For any questions, feedback, or concerns, feel free to reach out to me through the social media channels listed in my bio.
Further reading: