DynamoDB in 15 minutes
DynamoDB is a fully managed NoSQL database offering by AWS. It seems simple on the surface, but is also easy to misunderstand. In this post I introduce some of the basics that are required to understand DynamoDB and how it’s intended to be used. We’ll first take a look at the data structures inside DynamoDB, then talk about reading and writing to the database and also cover different kinds of indexes and access patterns before we move on to talking about performance and cost. We’ll end with a mention of some additional features and then come to a conclusion.
Since I intend to keep the scope of this manageable, I won’t go into too much detail on all of the features. That’s what the documentation and the other references I’ll mention in the end are for.
Data structures
Data in DynamoDB is organized in tables, which sounds just like tables in relational databases, but they’re different. Tables contain items that may have completely different attributes from one another. There is an exception though and that relates to how data is accessed. In DynamoDB you primarily access data on the basis of its primary key attributes and as a result of that, the attributes that make up the primary key are required for all items.

The primary key is what uniquely identifies an item in the table and it’s either a single attribute on an item (the partition key) or a composite primary key, which means that there is a combination of two attributes (partition key and sort key) that identify an item uniquely. Let’s look at some examples.
This example shows a table that has only a partition key as its primary key. That means whenever we want to efficiently get an item from the table, we have to know its partition key. Here you can also see that a single table can contain items with different structures.
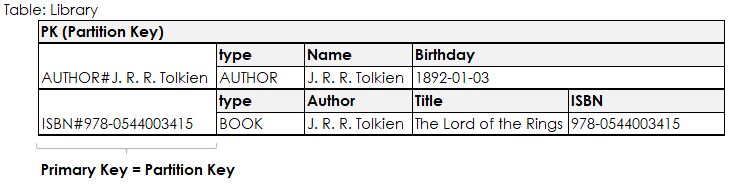
It’s more common to have a composite primary key on a table, which you can see below. This allows for different and more flexible query patterns. Items that share the same partition key value are called an item collection. The items in a collection can still be different entities.
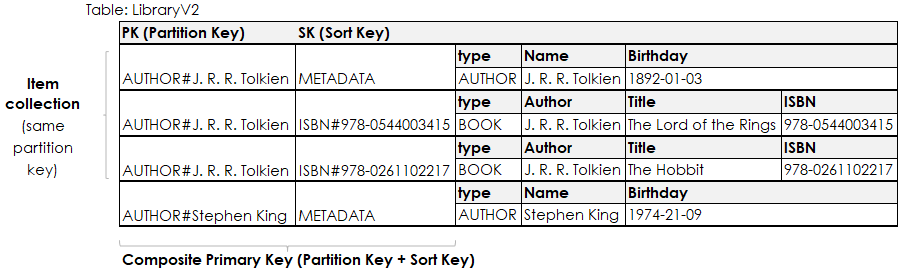
At this point I’d like to point out a few things about the table above.
You can see that it uses generic names for the partition and sort key attribute (PK and SK) and this is done on purpose.
When modelling data in DynamoDB we often try to put as many different entities into a single table as possible.
Since these entities are identified by different underlying attributes, it’s less confusing to have generic attribute names.
You can also see, that the values in the Key-Attributes are duplicated.
The number behind the ISBN# sort key is also a separate attribute, same with the author’s name.
This makes serialization and deserialization easier.
Putting all (or at least most) entities in a single table is the aptly named Single-Table-Design pattern.
To enable working with such a table, each item has a type attribute that we use to distinguish the different entities.
This makes deserialization more convenient.
Another effect of the single table design can be observed in the key attributes.
The actual values like “J. R. R. Tolkien” or “Stephen King” have a prefix.
This prefix acts as a namespace - it allows us to separate entities with the same key value but different type and helps to avoid key collisions inside of our table.
Let’s now talk about the different ways we can get data into and out of DynamoDB.
Reading and Writing data
The options to write to DynamoDB are essentially limited to four API-calls:
PutItem- Create or replace an item in a tableBatchPutItem- Same asPutItembut allows you to batch operations together to reduce the number of network requestsUpdateItem- Create a new item or update attributes on an existing itemDeleteItem- Delete a single item based on its primary key attributes
The details of these calls aren’t very interesting right now, let’s focus on reading data. For this we have a selection of another four API-Calls:
GetItem- retrieve a single item based on the values of its primary key attributesBatchGetItem- group multipleGetItemcalls in a batch to reduce the amount of network requestsQuery- get an item collection (all items with the same partition key) or filter in an item collections based on the sort keyScan- the equivalent of a table scan: access every item in a table and filter based on arbitrary attributes
The Scan operation is by far the slowest and most expensive, since it scans the whole table, so we try to avoid it at all cost.
We want to rely only on GetItem (and potentially BatchGetItem) and Query to fetch our data, because they are very fast operations.
Let’s visualize how these operations work.
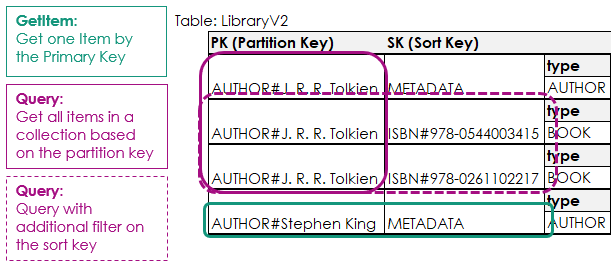
When we call GetItem we need to specify all primary key attributes to fetch exactly one item.
That means we need to know the partition and sort key in advance.
Getting the green item in Python can be achieved like this:
import boto3
def get_author_by_name(author_name: str) -> dict:
table = boto3.resource("dynamodb").Table("LibraryV2")
response = table.get_item(
Key={
"PK": f"AUTHOR#{author_name}",
"SK": "METADATA"
}
)
return response["Item"]
if __name__ == "__main__":
print(get_author_by_name("Stephen King"))
As you can see, I’ve specified both the partition and the sort key to uniquely identify an item. This API call is very efficient and will result in single-digit millisecond response times no matter how much data is in our table. Let’s take a look at a query example - in this case one that gets all author information:
import typing
import boto3
import boto3.dynamodb.conditions as conditions
def get_all_author_information(author_name: str) -> typing.List[dict]:
table = boto3.resource("dynamodb").Table("LibraryV2")
response = table.query(
KeyConditionExpression=conditions.Key("PK").eq(f"AUTHOR#{author_name}")
)
return response["Items"]
if __name__ == "__main__":
print(get_all_author_information("J. R. R. Tolkien"))
This function essentially returns the whole item collection of the author.
It’s equivalent to the violet query in the picture.
We can also add conditions on the sort key, which makes the Query operation quite powerful.
Here’s an example to fetch all books that an author wrote:
import typing
import boto3
import boto3.dynamodb.conditions as conditions
def get_books_by_author(author_name: str) -> typing.List[dict]:
table = boto3.resource("dynamodb").Table("LibraryV2")
response = table.query(
KeyConditionExpression=conditions.Key("PK").eq(f"AUTHOR#{author_name}") \
& conditions.Key("SK").begins_with("ISBN")
)
return response["Items"]
if __name__ == "__main__":
print(get_books_by_author("J. R. R. Tolkien"))
I’m using the ampersand & to chain the conditions.
The begins_with is one of the conditions supported to filter on the sort key - others are listed in the documentation.
Indexes
So far you’ve seen me use different ways to fetch data from our table.
All of these have been using attributes from the primary key.
What if we want to select data based on an attribute that’s not part of the primary key?
This is where things get interesting.
In a traditional relational database you’d just add a different WHERE condition to your query in order to fetch the data.
In DynamoDB there is the Scan operation you can use to select data based on arbitrary attributes, but it shares a similar problem as a where condition on unoptimized table in a relational database: it’s slow and expensive.
To make things faster in a relational database we add an index to a column and in DynamoDB we can do something similar. Indexes are very common in computer science. They’re secondary data structures that let you quickly locate data in a b-tree. We’ve already been using an index in the background - the primary index, which is made up of the primary key attributes. Fortunately that’s not the only index DynamoDB supports - we can add secondary indexes to our table which come in two varieties:
- The local secondary index (LSI) allows us to specify a different sort key on a table. In this case the partition key stays identical, but the sort key can change. LSIs have to be specified when we create a table and share the underlying performance characteristics of the table. When we create a local secondary index we also limit the size of each individual item collection to 10GB.
- The global secondary index (GSI) is more flexible, it allows us to create a different partition and sort key on a table whenever we want. It doesn’t share the read/write throughput of the underlying table and doesn’t limit our collection size. This will create a copy of our table with the different key schema in the background and replicate changes in the primary table asynchronously to this one.
Secondary indexes in DynamoDB are read only and only allow for eventually consistent reads.
The only API calls they support are Query and Scan - all other rely on the primary index.
In practice you’ll see a lot more GSIs than LSIs, because they’re more flexible.
How can these help us?
Suppose we want to be able to select a book by it’s ISBN.
If we take a look at our table so far, we notice that the ISBN is listed as a key attribute, which seems good at first glance.
Unfortunately it’s the sort key.
This means in order to quickly retrieve a book, we’d need to know it’s author as well as the ISBN for it (Scan isn’t practical with larger tables).
The way our table is layed out at the moment doesn’t really work well for us, let’s add a secondary index to help us answer the query.
The modified table is displayed below and has additional attributes that make up the global secondary index.
I’ve added the attributes GSI1PK as the partition key for the global secondary index and GSI1SK as the sort key.
The index itself is just named GSI1.
The attribute names that make up the index are very generic again, this allows us to use the GSI for multiple query patterns.
You can also see, that the GSI attributes are only filled for the book entities so far.
Only items that have the relevant attributes set are projected into the index, that means I couldn’t use the index to query for the author entities at the moment.
This is what’s called a sparse index.
Sparse indexes have benefits from a financial perspective, because the costs associated with them are lower.
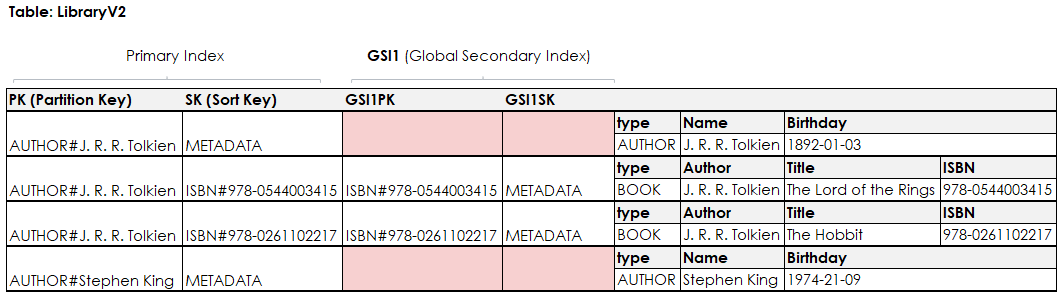
Back to our original question - how can we use this to fetch a book by its ISBN?
That’s now very easy, we can just use the Query API to do that, as the next code sample shows.
It’s very similar to a regular query, we just use different key attributes and specify the IndexName attribute to define which index to use (there can be multiple indexes on a table).
import boto3
import boto3.dynamodb.conditions as conditions
def get_book_by_isbn(isbn: str) -> dict:
table = boto3.resource("dynamodb").Table("LibraryV2")
response = table.query(
KeyConditionExpression=conditions.Key("GSI1PK").eq(f"ISBN#{isbn}") \
& conditions.Key("GSI1SK").eq("METADATA"),
IndexName="GSI1"
)
return response["Items"][0]
if __name__ == "__main__":
print(get_book_by_isbn("978-0544003415"))
You might wonder why GSI1 has a sort key that seems to be set to the static value METADATA for all items.
To implement this specific query pattern “Get a book by its ISBN”, a global secondary index with only a primary key would have been sufficient.
I still went with a partition and sort key, because it’s common to overload a secondary index.
This means you create a secondary index that not only fulfills one, but more than one query patterns.
In these cases it’s very useful to have a partition and sort key available.
By setting the sort key to a static value, we basically tell the system that there’s only going to be one of these items.
This has been an example on how you can use a global secondary index to enable different query patterns on our dataset. There are many more access patterns that can be modeled this way, but those will have to wait for future posts.
Let’s now talk about something different: performance and cost.
Performance & Cost
So far I’ve shown you some things about DynamoDBs data model and APIs but we haven’t talked about what makes it perform so well and how that relates to cost. DynamoDB has a few factors that influence performance and cost, which you can control:
- Data model
- Amount of data
- Read throughput
- Write throughput
The data model you implement has a major impact on performance.
If you set it up in a way that it relies on scan operations, it won’t hurt you too much with tiny databases, but it will be terrible at scale.
Aside from Scan all DynamoDB operations are designed to be quick at essentially any scale.
That however requires you to design your data model in a way that let’s you take advantage of that.
The amount of data has a limited influence on performance, which may even be negligible if you design your data model well. In combination with read and write throughput it may have an influence under certain conditions, but that would be a symptom of a poorly designed data model. The amount of data is a cost component - data in DynamoDB is billed per GB per month (around $0.25 - $0.37 depending on your region). Keep in mind that global secondary indexes are a separate table under the hood, that come with their own storage costs. This should be a motivation to use sparse indexes.
Whenever your read from or write to your table you consume what’s called read and write capacity units (RCU/WCU). These RCUs or WCUs are how you configure the throughput your table is able to handle and there are two options you can do this with:
- Provisioned Capacity: You specify the amount of RCUs/WCUs for your table and that’s all there is.
If you use more throughput than you have provisioned, you’ll get a
ProvisionedThroughputExceededexception. This can be integrated with AutoScaling to respond to changes in demand. This billing model is fairly well predictable. - On-Demand Capacity: DynamoDB will automatically scale the RCUs and WCUs for you, but individual RCUs and WCUs are a little bit more expensive. You’re billed for the amount of RCUs/WCUs you use. This mode is really nice when you get started and don’t know your load patterns yet or you have very spiky access patterns.
A general recommendation is to start with on-demand capacity mode, observe the amount of consumed capacity and once the app is fairly stable switch to provisioned capacity with Auto Scaling. You should be aware that secondary indexes differ in the way they use the capacity. Local secondary indexes share the capacity with the underlying base table whereas global secondary indexes have their own capacity settings.
Since this is supposed to be a short introduction to DynamoDB we don’t have time to go over all the details, but there are nevertheless some features I’d like to briefly mention.
Additional features
DynamoDB offers many other useful features. Here are a few I’d like to mention:
- DynamoDB Streams allow you perform change-data-capture (CDC) on your DynamoDB table and respond to updates in your table using Lambda functions. You can also pipe these changes into a Kinesis data stream.
- Transactions allow you to do all-or-nothing operations across different items.
- DynamoDB Global Tables is a feature that allows you to create Multi-Region Multi-Master setups across the globe with minimal latency.
- PartiQL is a query language designed by AWS that’s similar to SQL and can be used across different NoSQL offerings.
- DAX or the DynamoDB Accelerator is an in-memory write-through cache in front of DynamoDB if you need microsecond response times.
Conclusion
We have looked at a few key aspects of DynamoDB that should give you a good basic understanding of the service and will help you with further reasearch. First we discussed tables, items, keys and item collections, which are the basic building blocks of DynamoDB. Then we moved on to the API calls you use to fetch and manipulate data in the tables before moving on to the two types of secondary indexes. Performance and cost were also aspects we’ve discussed and in the end I mentioned a few other key features.
If you want to play around with the tables I’ve mentioned in this post, you can find the code for that on github.
Thank you for your time, I hope you gained something from this article. If you have questions, feedback or want to get in touch to discuss projects, feel free to reach out to me over the social media I’ve listed in my bio below.
— Maurice
Additional Ressources
Here is a list of additional resources you might want to check out. I can highly recommend anything done by Rick Houlihan. The DynamoDB book is also very well written and a great resource if you want to do a deep dive. If you’re curious about the techniques that make DynamoDB work, the talk by Jaso Sorensen is a good resource.
- dynamodbbook.com - The book about DynamoDB by Alex DeBrie
- dynamodbguide.com
- AWS re:Invent 2018: Amazon DynamoDB Under the Hood: How We Built a Hyper-Scale Database (DAT321) - by Jaso Sorensen
- AWS re:Invent 2018: Amazon DynamoDB Deep Dive: Advanced Design Patterns for DynamoDB (DAT401) - by Rick Houlihan
- AWS re:Invent 2019: Data modeling with Amazon DynamoDB (CMY304) - by Alex DeBrie
- AWS re:Invent 2019: [REPEAT 1] Amazon DynamoDB deep dive: Advanced design patterns (DAT403-R1) - by Rick Houlihan