Start Guessing Capacity - Benchmark EC2 Instances
Stop guessing capacity! - Start calculating.
If you migrate an older server to the AWS Cloud using EC2 instances, the prefered way is to start with a good guess and then rightsize with CloudWatch metric data.
But sometimes you’ve got no clue, where to start. And: Did you think all AWS vCPUs are created equal?
No, not at all. The compute power of different instance types is - yes - different.
Benchmark Instances with 7zip
I’ve got no clue - what to do?
To start with an educated guess, you need a simple benchmark which runs in the cloud and on old Windows and Linux machines. Introducing my old friend: the 7zip. This is an efficient compression program, see 7Zip. It started 1999, so it is available for older servers as well.
This program comes with an embedded CPU benchmark. I will use this benchmark to compare the EC2 vCPU of different .large instance types. To get an exact benchmark, you would have to run it many times to get statistically significant value. Because nowadays in post DOS-single tasking environments, many apps on a instance compete for compute resources. But for an educated starting guess, it fits the purpose.
And speaking of older instances - there are already many existing results at 7-cpu.com.
Calculating the Instance Type
The calculation on linux instances is automated, with windows you currently have to start it manually.
Getting Benchmark Results on Windows
After downloading 7zip here, you start it with the b parameter and get the results:
./7z.exe b
7-Zip 19.00 (x64) : Copyright (c) 1999-2018 Igor Pavlov : 2019-02-21
Windows 10.0 17763
x64 6.3F02 cpus:2 128T
CMPXCHG MMX SSE RDTSC PAE SSE2 NX SSE3 CMPXCHG16B XSAVE RDWRFSGSBASE FASTFAIL RDRAND RDTSCP
Intel(R) Xeon(R) CPU E5-2676 v3 @ 2.40GHz (306F2)
CPU Freq: 2064 4000 2064 4266 2031 2723 2737 2618 2677
RAM size: 8191 MB, # CPU hardware threads: 2
RAM usage: 441 MB, # Benchmark threads: 2
Compressing | Decompressing
Dict Speed Usage R/U Rating | Speed Usage R/U Rating
KiB/s % MIPS MIPS | KiB/s % MIPS MIPS
22: 7098 155 4465 6906 | 103740 200 4428 8857
23: 7135 157 4641 7270 | 102741 200 4447 8893
24: 6879 171 4320 7396 | 98914 199 4356 8684
25: 6464 161 4587 7381 | 97762 200 4349 8702
---------------------------------- | ------------------------------
Avr: 161 4503 7238 | 200 4395 8784
Tot: 180 4449 8011
I am using the compression and decompression rating average MIPS to compare the type.
So the 7zip bench here would be 7238+8784=16022
If this is our data from the to-be-migrated server, what instance type to choose?
Comparing large EC2 Instance Types
I want to have a fast result. Also, I want it to be automated, so I can easily add new types. Additionally, I want security from the beginning. Last, because I am also testing pricier instances, I want these instances to self destruct.
So my approach is to start n instances at the same time and let them self destruct after the work is done.
Overview
Instance identification preparation
Because I want to know the instance type afterwards, the script has to access the instance metadata.
- Get imdsv2 compatible metatdata to determine instance type, id and size
- For linux, windows and different processor types
Instance creation and Benchmark calculation
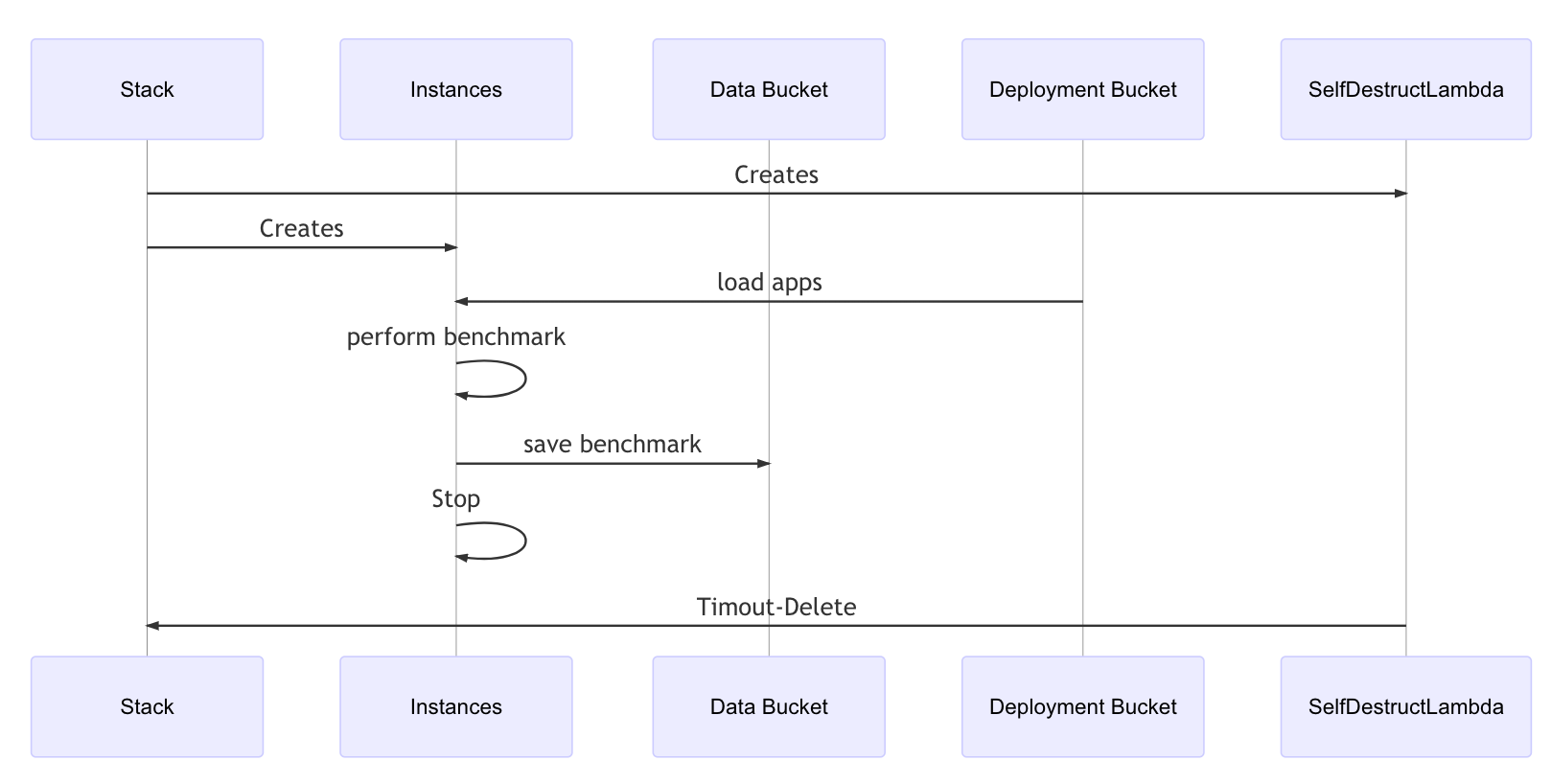
- create instances in parallel with CDK
- calculate benchmark
- store data
- instances stop themselves
- stacks destroy themselves
- get data from data bucket
Analyzing the data
For now I did not automate the data capture. That would be a good next step.
Displaying the Data
To compare data, a R programm is used.
Code in Detail
Creating Instances with the CDK
We distinguish between “normal” x86 and ARM cpus. All instances are collected in an array Instances.
X86
var amiLinuxX86_64 = new AmazonLinuxImage({
cpuType: AmazonLinuxCpuType.X86_64,
edition: AmazonLinuxEdition.STANDARD,
generation: AmazonLinuxGeneration.AMAZON_LINUX_2
})
// *
var instances: Instance[] = new Array<Instance>();
const testedInstanceC4 = new Instance(this, 'testedInstanceC4', {
instanceType: InstanceType.of(InstanceClass.COMPUTE4, InstanceSize.LARGE),
machineImage: amiLinuxX86_64,
userData: UserData.custom(userdata),
vpc: testVpc,
vpcSubnets: {subnetType: SubnetType.PUBLIC},
securityGroup: sg
})
instances.push(testedInstanceC4);
ARM
var amiLinuxG = new AmazonLinuxImage({
cpuType: AmazonLinuxCpuType.ARM_64,
edition: AmazonLinuxEdition.STANDARD,
generation: AmazonLinuxGeneration.AMAZON_LINUX_2
})
const testedInstanceM6G = new Instance(this, 'testedInstanceM6G', {
instanceType: InstanceType.of(InstanceClass.M6G, InstanceSize.LARGE),
machineImage: amiLinuxG,
userData: UserData.custom(userdataArm),
vpc: testVpc,
vpcSubnets: {subnetType: SubnetType.PUBLIC},
securityGroup: sg
})
instances.push(testedInstanceM6G);
To get the instance metadata, we need the program ec2-imds compiled for Linux, Linux-arm and windows.
So i took ec2-imds and added a Taskfile to cross-compile. See Taskfile in ec2-imds:
- GOOS=linux GOARCH=amd64 go build -o dist/ec2-imds-linux {{.FILE}}
- GOOS=windows GOARCH=amd64 go build -o dist/ec2-imds-windows {{.FILE}}
- GOOS=linux GOARCH=arm64 go build -o dist/ec2-imds-linux-arm {{.FILE}}
Userdata
The instances have a boot-script (see bootstrap/userdata.sh), which instruments the benchmark.
- Install 7zip
sudo amazon-linux-extras install epel -y
sudo yum install p7zip -y
- get binaries from bucket (uploaded with cdk)
export deploy="DEPLOYMENT"
aws s3 cp s3://${deploy}/IMDS .
chmod u+x IMDS
- create benchmark data
7za b >${benchfile}
- Copy to data bucket
aws s3 cp ${benchfile} s3://${outout}/${instanceid}.txt
- Stop instance
aws ec2 stop-instances --instance-ids "${instanceid}" --region REGION
The dynamic data like bucket name is injected with the cdk:
var userdata = readFileSync(userDataFile, 'utf8').toString();
userdata = userdata.replace(/BUCKET/g, benchData.bucketName);
userdata = userdata.replace(/DEPLOYMENT/g, benchDeployment.bucketName);
userdata = userdata.replace(/REGION/g, this.region);
The name of the data bucket is stored in an CloudFormation export:
const benchData = new Bucket(this, "BenchData",{
removalPolicy: RemovalPolicy.RETAIN
});
new CfnOutput(this, "dataBucket",
{
value: benchData.bucketName,
exportName: "benchdata"
})
The get-data task uses this export to sync the data:
get-data:
desc: Load data from bucket
dir: data
vars:
bucket:
sh: aws cloudformation list-exports --query 'Exports[?Name==`benchdata`].Value' --output text
cmds:
- aws s3 sync s3://{{.bucket}} .
Running
While you run with ./scripts/perform-bench.sh, you see that the faster instances are finished, while the slower ones still are in state “running”.
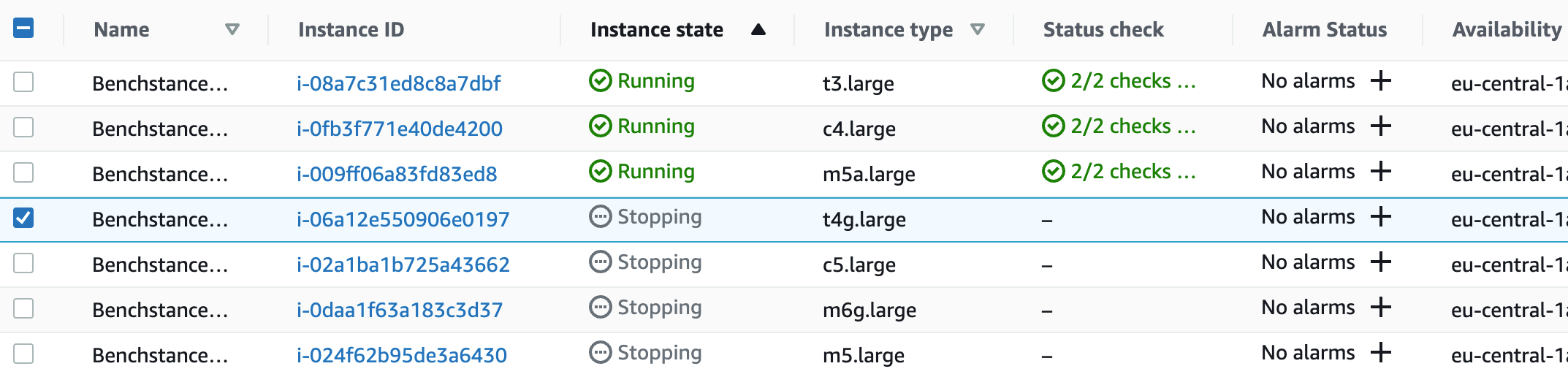
Results
The results from the scripts for Linux instances look like this:
7-Zip (a) [64] 16.02 : Copyright (c) 1999-2016 Igor Pavlov : 2016-05-21
p7zip Version 16.02 (locale=C,Utf16=off,HugeFiles=on,64 bits,2 CPUs Intel(R) Xeon(R) CPU E5-2676 v3 @ 2.40GHz (306F2),ASM,AES-NI)
Intel(R) Xeon(R) CPU E5-2676 v3 @ 2.40GHz (306F2)
CPU Freq: 2685 2686 2685 2683 2683 2688 2684 2687 2688
RAM size: 7974 MB, # CPU hardware threads: 2
RAM usage: 441 MB, # Benchmark threads: 2
Compressing | Decompressing
Dict Speed Usage R/U Rating | Speed Usage R/U Rating
KiB/s % MIPS MIPS | KiB/s % MIPS MIPS
22: 6171 161 3735 6003 | 65320 200 2789 5577
23: 6080 166 3736 6195 | 64362 200 2786 5571
24: 5775 166 3735 6210 | 63657 200 2795 5588
25: 5984 176 3878 6832 | 62638 200 2789 5575
---------------------------------- | ------------------------------
Avr: 167 3771 6310 | 200 2790 5578
Tot: 184 3280 5944
instance-type: t2.large
instance-id: i-0a04a2211c6345211
With that, we create a csv file:
type;vcpu;compressing;decompressing
m6g.large;2;7118;6922
c5.large;2;6070;4703
c4.large;2;5350;4415
t2.large;2;6310;5578
t3.large;2;3637;4176
t4g.large;2;6959;6943
m5a.large;2;4029;3939
m5.large;2;5571;4304
Diagram Creation with R
And feed it into a small R script
library(readr)
library(ggplot2)
df <- read.csv2("benchmarks.csv")
bp <- barplot(t(df[ , -1]), col = c("blue", "red", "green", "orange", "gold"))
axis(side = 1, at = bp, labels = df$type)
ggplot(data=df, aes(x=type, y=compressing+decompressing, fill=type)) +
geom_bar(stat="identity", position=position_dodge())+
geom_text(aes(label=type), vjust=1.6, color="white",
position = position_dodge(0.9), size=3.5)+
scale_fill_brewer(palette="Paired")+
theme_classic()
to create a nice barplot.
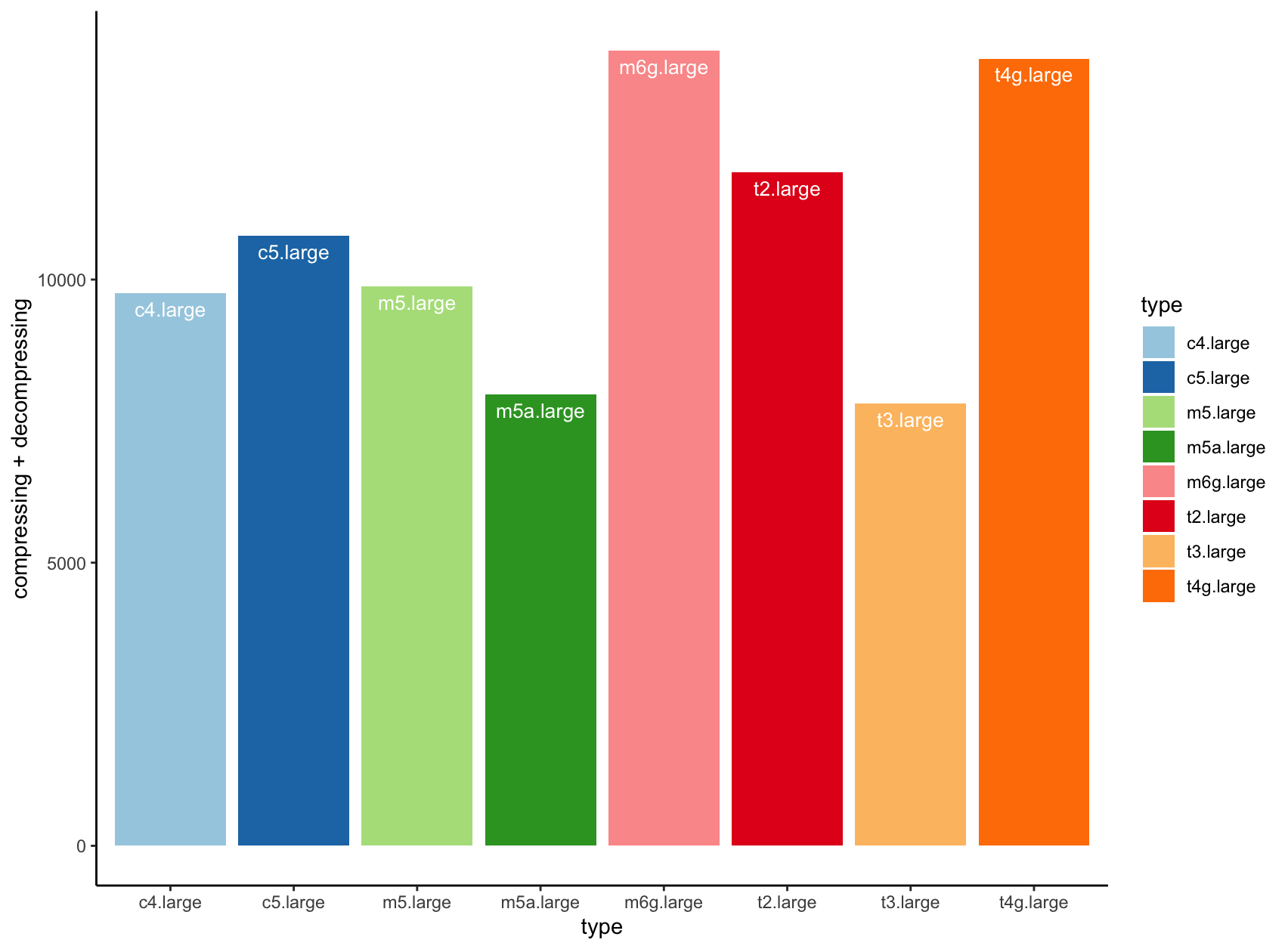
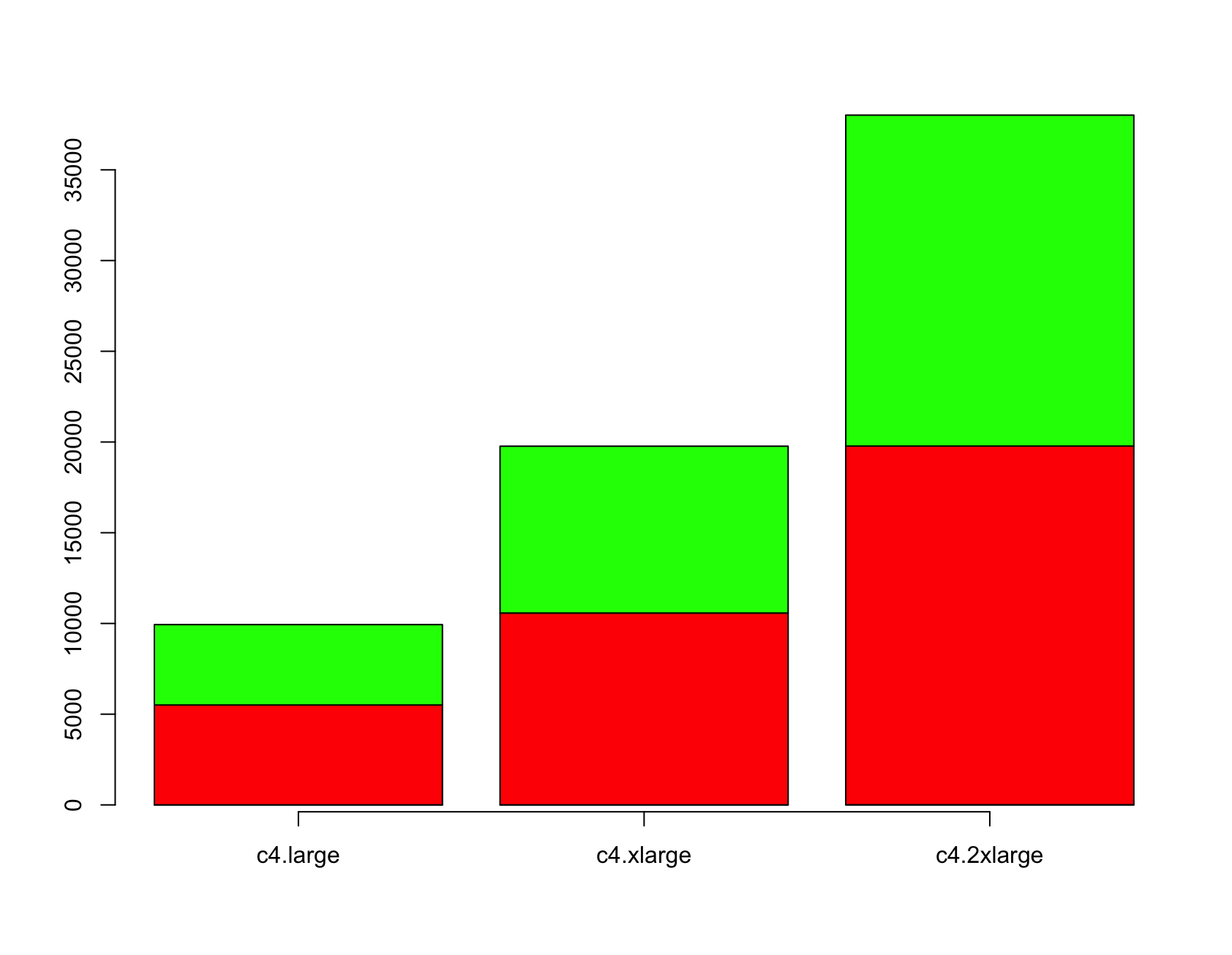
And we see, that the m6g performance really rocks! And with instance types with more vCPUs you just multiply the base value.
Verify this assumption with a calculation:
instanceType: InstanceType.of(InstanceClass.COMPUTE4, InstanceSize.LARGE),
...
instanceType: InstanceType.of(InstanceClass.COMPUTE4, InstanceSize.XLARGE),
...
instanceType: InstanceType.of(InstanceClass.COMPUTE4, InstanceSize.XLARGE2),
Summary
With this approach, you have a framework to benchmark instance-based settings. Additional programs to support your use case should be written in go, which is the most portable and fast solution if you compare the current scripting solutions like node, python, ruby. (Ok, rust is on the way…)
So choosing the first instance type for migration could be a few simple steps:
- Running 7zip on an old instance, getting
oldbench - Determine whether the software may run on arm-based processors
- Comparing
oldbenchto ec2 benchmarks - Double vCPUs (large=>xlarge=>…) if needed
It is still to be analyzed, whether Linux bases 7zip and Windows based 7zip have equal MIPS.
Sources
Sources on github
Did you find this approach useful? If you have additional Ideas, Questions, Additions, Feedback - just contact me on twitter (@megaproaktiv).
Title image C6 icon is taken from the awesome AWS simple icons.