Wer ist der Schnellste? Überblick über AWS Ressourcen mit Polyglot Programming.
tl;dr - asynchrone Programmierung ist sehr viel schneller als sequentielle Aufrufe. Insofern stimmt das Pferdebild gar nicht, aber ein einzelnes Pferd sieht halt nicht so spannend aus… Außerdem bin ich selber über die Unterschiede in der Ausführungszeit überrascht… Eine Analyse am Anwendungsfall “wie bekomme ich den Überblick über AWS Resourcen über alle Regionen mit minimaler Ausführungszeit. Am Rennen nehmen teil: node, python und go. Und - um die Aufschreie der jeweiligen Fans vorwegzunehmen - es geht mehr um das Paradigma asynchron als um die Sprache. Ganz nebenbei seht ihr die AWS SDKs im Vergleich! Aber lest selbst
Der Anwendungsfall
Alle Resourcen - alle Regionen
Für die folgenden Services will ich schnell eine Übersicht bekommen.
- ApiGateway
- S3Buckets-
- EC2
- Elastiv Load Balancers
- ElasticsearchDomains
- RDS
- Lambda
- Cloudformation Stacks
Erstmal interessiert nur die Anzahl der Ressourcen für einen schnelle Übersicht. Denn - das kann ich aus leidiger Erfahrung sagen: Wenn man in verschiedenen AWS Regionen unterwegs ist, vergisst man schnell einmal eine Instanz in Virginia…
Also: alles und schnell!
Um zu sehen, welche Geschwindigkeitsunterschiede es gibt, vergleichen wir hier drei verschiedene Sprachen und Ansätze.
Messmethode
Wir analysieren go, node und python auf Ausführungsgeschwindigkeit und Programmierparadigma. Das soll nicht bedeuten, dass die jeweiligen Konzepte nicht auch in den anderen Sprachen realisierbar sind. Ich habe nur das “Standard” Vorgehen der jeweiligen Sprache verwendet. Hier will ich mehr die Ansätze vergleichen, wobei ein kleiner Vergleich der Sprachen nicht ausbleibt.
Dazu nehme ich das time Kommando um die Programme lokal auszuführen. Nach jedem Aufruf füge ich eine 10 Sekunden Pause ein, sonst bekommt man schnell “to much requests” Fehler von AWS.
Bandbreite ist genug da und auf dem Rechner laufen (fast) keine anderen Programme. Um “Rauschen” auszuschließen führe ich die Programme jeweils 10 mal aus. Die Standardabweichung der Werte gibt dann eine Idee darüber, wie groß die Streuung der Ergebnisse ist.
#!/bin/bash
date >>go.log
echo "START GO ========" >>go.log
for i in 0 1 2 3 4 5 6 7 8 9
do
date
echo $i
date >>go.log
time (aws-overview )2>>go.log
sleep 10
done
echo "END ========" >>go.log
Das “time” Kommando gibt dann den Zeitverbrauch aus:
real 0m0.166s
user 0m0.062s
sys 0m0.077s
Zeit für einen Kaffee - nachdem die “go.log” und die anderen Dateien erstellt wurden baue ich diese manuell (grmpfh) in eine csv Datei um:
lang,real,user,sys
go,0m0.148s,0m0.053s,0m0.046s
...
node,0m12.598s,0m1.202s,0m0.172s
...
python,0m43.551s,0m2.494s,0m0.412s
...
Der Unterschied zwischen der “user” und der “sys(tem)” Zeit besteht darin, dass die Zeit im Kernel oder im Anwenderbereich verbraucht wurde. Dabei ist der Anwenderbereich z.B. das Programm oder Bibliotheken. Wenn dass vom Betriebssystem z.B. ein “Datei öffnen” Aufruf gemacht wird, ist das Systemzeit. Das erinnert ein wenig an Großrechnerzeiten, in denen man Zeitscheiben zugewiesen bekommen hat.
So, jetzt möchte ich ein paar nette Diagramme haben, um die Zahlen zu interpretieren. Das geht schnell und einfach (wenn man R kennt):
speed <- transform(speedIn, lang = as.character(lang), speed=(as.numeric(substring(user,3,7))+as.numeric(substring(sys,3,7))),
real=(as.numeric(substring(real,3,7))))
ggplot(speed, aes(y= speed, x=lang)) + geom_boxplot()
Nun können wir die Sprachen und Ansätze vergleichen:
Sprachen und Ansätze
go - parallele Ausführung
Ich habe das Repository https://github.com/partamonov/aws-overview nach https://github.com/tecracer/aws-overview geforkt und dort etwas erweitert. In diesem Programm werden goroutines verwendet um die Anforderungen an die AWS Webservices zu stellen. In go werden die Programme zu ausführbaren Binärdateien kompiliert.
Damit kann man auch einfach Binaries für andere Betriebssysteme erzeugen. Außerdem ist go statisch typisiert, d.h. man muss die Variablen und Datenstrukturen immer vor Benutzung definieren. Das ist am Anfang etwas anstrengender, führt dafür zu meist fehlerärmeren Programmen.
Dieser Teil des Go Programms zählt die Lambda Ressourcen:
package main
import (
"github.com/aws/aws-sdk-go/aws"
"github.com/aws/aws-sdk-go/aws/session"
"github.com/aws/aws-sdk-go/service/lambda"
"log"
)
func listLambda(region string, verbose bool) (lambdaNumber int) {
svc := lambda.New(session.New(&aws.Config{Region: aws.String(region)}))
params := &lambda.ListFunctionsInput{
MaxItems: aws.Int64(100),
}
resp, err := svc.ListFunctions(params)
if err != nil {
log.Fatal("Cannot get Lambda data: ", err)
}
if verbose {
for _, name := range resp.Functions {
log.Println("Lambda Name: ", *name.FunctionName)
}
}
lambdaNumber = len(resp.Functions)
return lambdaNumber
}
Die Funktion wird als goroutine aufgerufen und damit parallel ausgeführt:
wg.Add(1)
go func() {
defer wg.Done()
rLambdaTotal := listLambda(region, verbose)
Am Ende des Programms wird gewartet, bis alle Aufrufe fertig sind:
wg.Wait()
Node - asynchrone Ausführung der Services
Node.js ist eine interpretierte Sprache. Dieses Beispiel-Script verwendet promises, um alle Anfragen zu gleichzeitigen Ausführung an AWS zu senden und am Ende die Ergebnisse einzusammeln.
// AWS Lambda
servicefinder.push(
new AWS.Lambda().listFunctions({}).promise().then((data) => {
return inventory.push({
service: "AWS Lambda (functions)",
count: data.Functions.length
})
})
)
Diese Implementierung ist etwas kürzer, da keine “verbose” Funktionalität vorhanden ist, die die Namen der Lambdas ausgibt. Auf das Zeitverhalten hat das wenig Einfluss.
Python mit sequentiellen Abarbeitung
Dieses Script habe ich von https://github.com/arndtroth/AWSomeOverview verwendet.
Dieser Ansatz ruft die Services sequentiell auf. Das bedeutet, dass das Programm erst darauf wartet, bis die Antwort für den ersten Aufruf da ist, bevor der zweite Aufruf gesendet wird. Das dauert natürlich “etwas” länger. Das Programm ist mit Service Klassen geschrieben.
Die Lambda Ressource ist hier (noch) nicht interpretiert, aber das Prinzip beim EC2 Zählen ist ähnlich. Das AWS Command Line Interface (CLI) verwendet selber Python, daher kann man davon ausgehen dass das Python SDK, genannt “Boto 3” immer gut gepflegt ist…
Siehe: aws cli requirements.txt
"""
Class for Data Extraction of EC2 instances
"""
import boto3
from deplugins.base import AWSFact
class EC2 (AWSFact):
NAME = "EC2"
OPTION = 'ec2'
ORDERED_HEADINGS = [
'AZ', 'VPC ID', 'ID', 'State', "Type", 'AMI', 'DevType',
"EBS Optimized", 'Key Owner',
"Public IP", "Private IP"
]
def retrieve(self, conn):
for element in conn.instances.all():
item = {
'ID': element.id,
"EBS Optimized": element.ebs_optimized,
#...
'State': element.state['Name'],
'AZ': element.placement['AvailabilityZone'],
'VPC ID': element.vpc_id,
}
self.data[conn.region_name].append(item)
def connect(self, region):
conn = boto3.resource('ec2', region_name=region)
conn.region_name = region
return conn
Zeitvergleich
Ausführungszeit User und System
Ein paar Zeilen R zählen User und System Zeit zusammen
speedIn <- read.csv("overview-timing.csv", sep = ",", header = TRUE)
speed <- transform(speedIn, lang = as.character(lang), speed=(as.numeric(substring(user,3,7))+as.numeric(substring(sys,3,7))),
real=(as.numeric(substring(real,3,7))))
Um die Ergebnisse dann darzustellen (Zeit in Sekunden):
library(ggplot2)
ggplot(speed, aes(y= speed, x=lang)) + geom_boxplot()
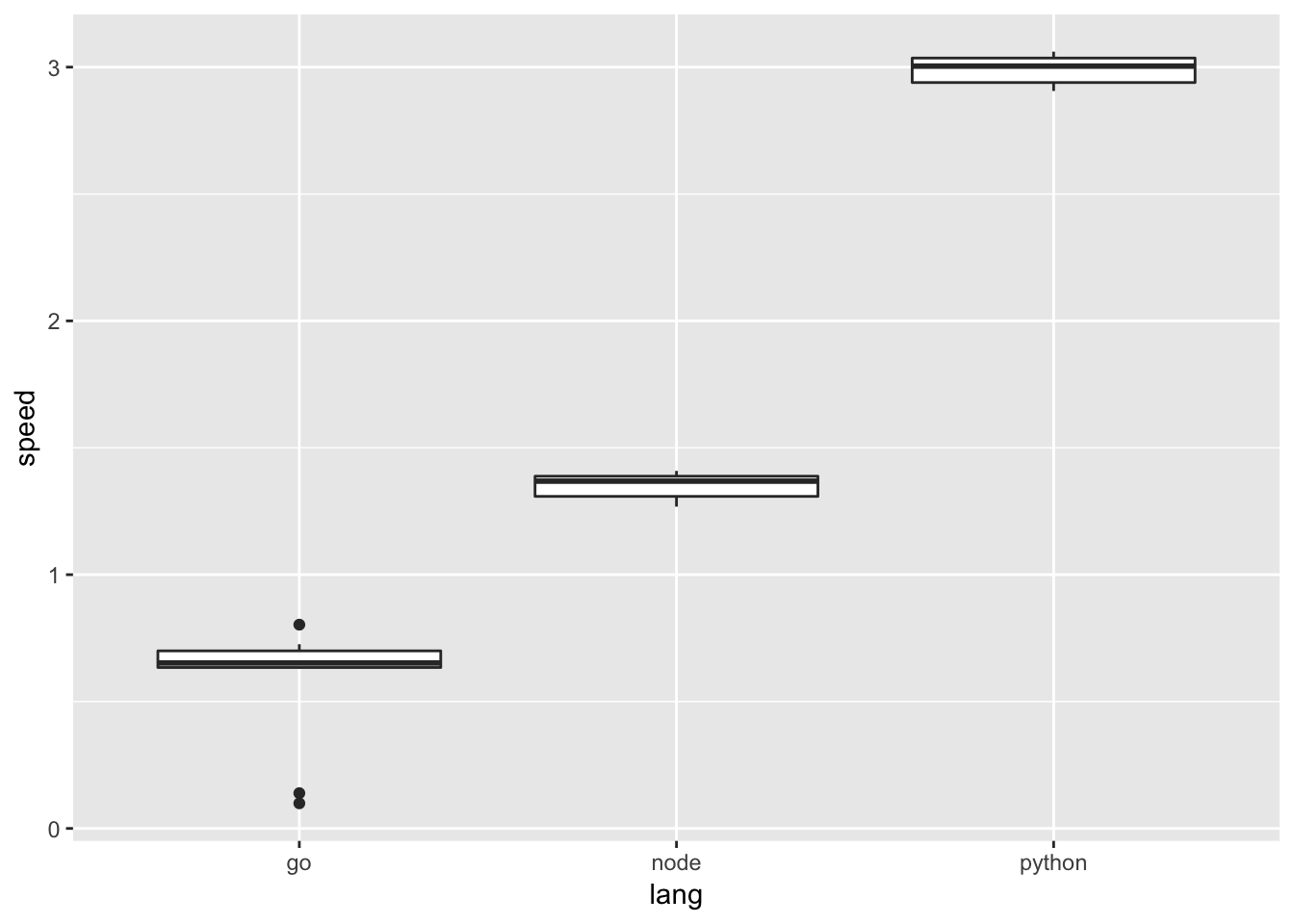
Hier ist parallele, kompilierte Ausführung der klare Gewinner! Wer seinen Wetteinsatz auf die anderen Sprachen gesetzt hat, her mit dem Geld!
Gesamtausführungszeit
Eine weitere Zeile R zeigt uns die Gesamtausführungszeit.
ggplot(speed, aes(y= real, x=lang)) + geom_boxplot()
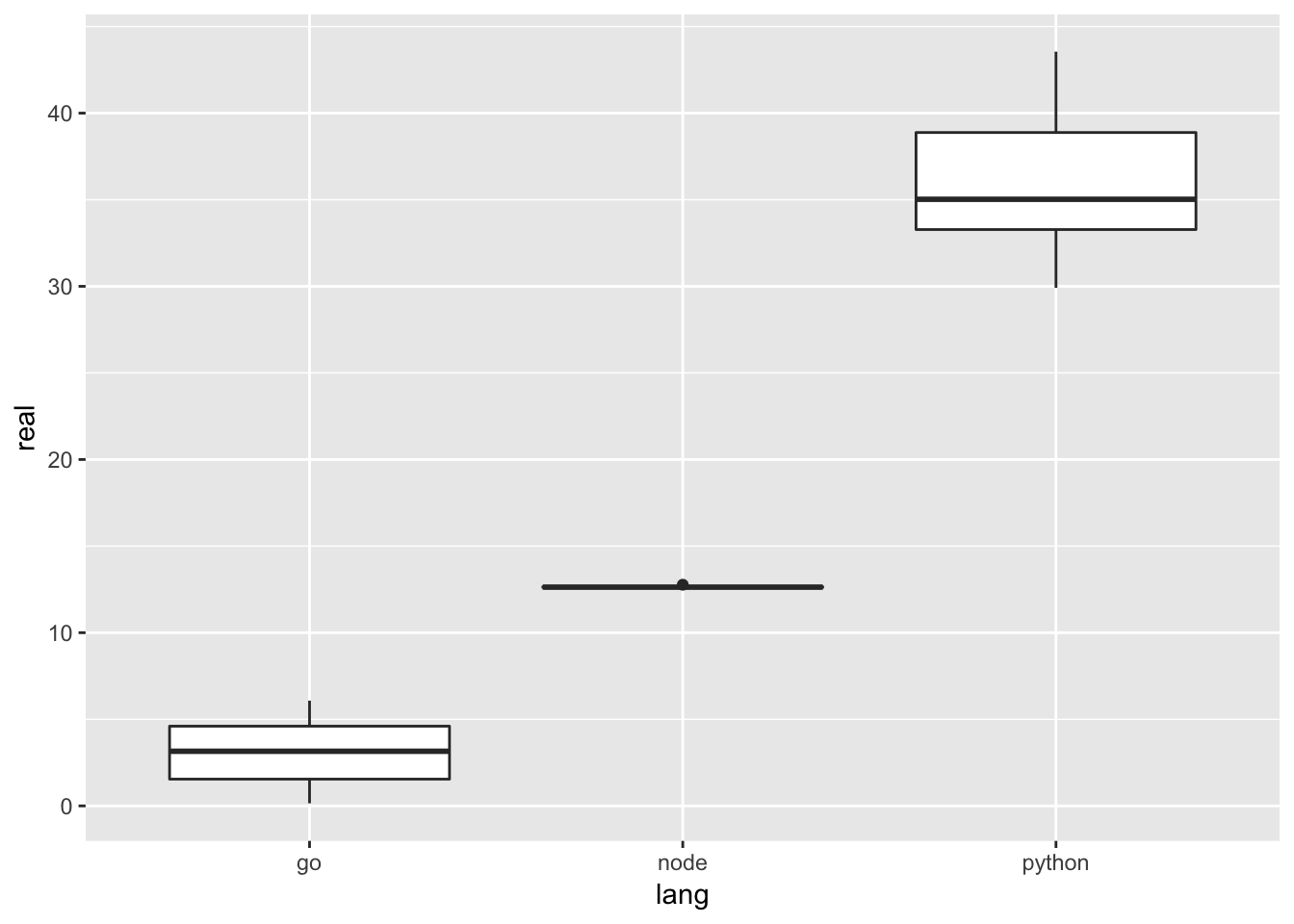
Fazit
Die Diagramme zeigen, dass durch asynchrone bzw. parallele Ausführung der aws-Serviceanfragen viel Zeit gespart werden kann. Die parallele Ausführung in der kompilierten go-Binärdatei ist um das * 10-fache schneller als das interpretierte Python-Skript!
Die Wahl der richtigen Sprache hängt also davon ab, wie oft Sie das Programm ausführen möchten. Mit Lambda bezahlen Sie für die Ausführungszeit, also lohnt es sich vielleicht, Programmierparadigmen oder Sprachen zu wechseln!
Anhang
Quellen
- Go Programm aws-overview
- Python AWSomeOverview